一、什么是索引?
索引(Index)是帮助 MySQL 高效获取数据的数据结构。
索引的应用在生活中很常见,例如图书的目录、词典等,都是通过不断的缩小想要获得数据的范围来筛选出最终想要的结果。
二、索引的数据结构
数据库中的数据是存储在磁盘中的,磁盘 IO 是十分高昂的操作,所以每次查找数据的时候需要把磁盘 IO 控制在一个很小的数量级,由此就引出了 B/B+ 树的数据结构。
B - Tree
又称平衡多路查找树,为了减少磁盘 IO 查找次数,尽量要把数据结构设计成「矮胖」,B - Tree 就满足这一特征。
一个 M 阶的 B - Tree 有如下特征:
- 定义任意非叶子结点最多只有 M 个儿子,且 M > 2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整;
- 非叶子结点的关键字个数 = 儿子数 - 1;
- 所有叶子结点位于同一层;
- k 个关键字把节点拆成 k + 1 段,分别指向 k + 1 个儿子,同时满足查找树的大小关系。

B - Tree 相对平衡二叉树而言,每个结点包含的关键字多了,树的层级更少了,从而减少了数据查找的次数和复杂度。
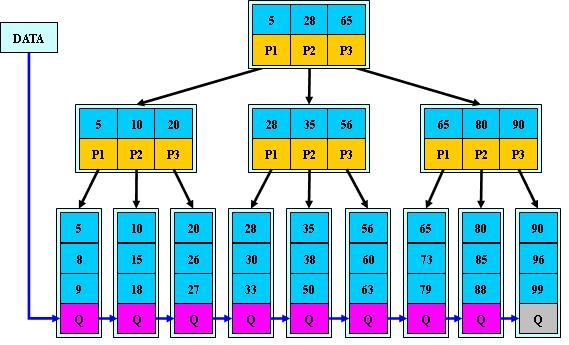
B+ - Tree
B+ - Tree 是 B - Tree 的升级版。
规则如下:
- B+ - Tree 的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得 B+ - Tree 每个非叶子节点所能保存的关键字大大增加;
- B+ - Tree 叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样;
- B+ - Tree 叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针;
三、索引类型
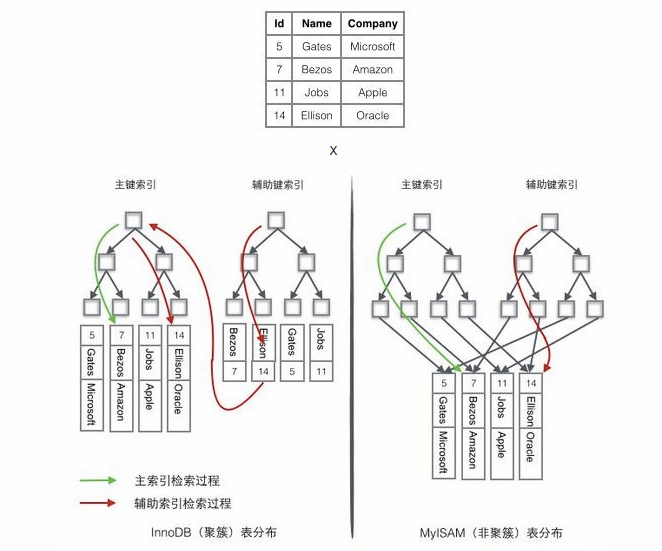
在 MySQL 中,索引分为两大类:聚簇索引和非聚簇索引。
InnoDB 使用的是聚簇索引,聚簇索引是按照数据存放的物理位置为顺序的,将行数据存储到叶子节点上。有主键时,根据主键创建聚簇索引;没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引。
MyISAM 使用的是非聚簇索引,非聚簇索引叶子节点存储的不是数据本身,而是存放数据的地址。
在这两大类的索引类型下,还可以将索引分成四个小类:
-
普通索引:最基本的索引,没有任何限制。
-
唯一索引:索引列的值必须唯一,但允许有空值。
-
全文索引:仅可以适用于 MyISAM 引擎的数据表,用于查找文本中的关键词,而不是直接比较是否相等。
-
组合索引:将几个列作为一条索引进行检索,使用最左匹配原则。
如果一个索引包含所有需要查询的字段的值,则成为覆盖索引。
覆盖索引只需要扫描索引,不需要回表,极大的减少了数据访问量。